Data Governance: Vom Model Driven Design (MDD) zum Data Catalog
Wie Organisationen von einer lückenhaften Nachdokumentierung zu einem transparenten Datenmanagement kommen.
Herausforderung von Data Governance
Eines der Ziele von Data Governance ist es eine möglichst gute Transparenz über die Verarbeitung und Verwendung von Daten über die Systeme hinweg herzustellen, um den Grad der Compliance-Konformität festzustellen und stetig zu monitoren sowie ein compliance-konformes Verhalten beim Umgang mit Daten zu fördern. Zusätzlich ermöglicht die Transparenz stetig Schwächen der Leistungsfähigkeit von Daten zu erkennen und Maßnahmen zur Verbesserung abzuleiten. Dies fördert die Qualität von Datenanalyse- und Digitalisierungsprojekten.
Eine der großen Herausforderungen - zur Erreichung eines transparenten Datenmanagements - ist es die dafür nötigen Informationen zu erhalten, aufzubereiten und nutzerfreundlich zur Verfügung zu stellen. Bereits zu Beginn solcher Initiativen gestaltet es sich schwierig, die nötigen Informationen zu finden, da diese meist nicht dokumentiert vorhanden sind, oder sehr lückenhaft und häufig nicht im nötigen Kontext miteinander stehen. Darüber hinaus liegen die Informationen in sehr unterschiedlichen Formaten und Strukturen vor. Ein Großteil der Informationen existiert meist nur in den Köpfen der Mitarbeiter. Daher sind sog. Data Catalog oder Meta Data Management Projekte immer sehr langläufig und aufwändig. Man hat ständig das Gefühl, immer der Aktualität hinterher zu sein. Klar ist, Dokumentation ist kein geliebtes Thema und es wird überwiegend keine Zeit dafür eingeplant. Sollte doch mal dokumentiert werden, dann erst zum Schluss, nachdem schon ein Teil des Wissens in den Köpfen verblasst ist.
Die Idee
Mit dieser scheinbaren Gegebenheit wollten wir uns im Unternehmen nicht zufriedengeben. Unsere Vorstellung war es, dass es doch eine Möglichkeit geben muss, Dokumentation als proaktiven und stetig nutzvollen Begleitprozess in unseren BI Projekten zu etablieren. Folgende Anforderungen sollte das neue Verfahren möglichst erfüllen, um einen hohen Mehrwert für die Stakeholder zu generieren:
- Das wesentliche Wissen einfach und zeitnah festhalten, ohne dass es zeitlich als störend empfunden wird. (Was für den Informationenbedarf nicht notwendig ist und daher keinen Mehrwert hat, wird weggelassen.)
- Möglichst datenbasiert und somit jederzeit auswertbar, wiederverwendbar und steuerbar.
- Es soll als verständliches Kommunikationsmittel an den Schnittstellen zwischen den Prozessbeteiligten dienen und somit für ein qualitatives und effektives Miteinander sorgen.
- Die Informationen liegen zentral vor und alle Stakeholder können zu jederzeit auf die gewünschten Informationen zugreifen.
- Datenverarbeitungsprozesse sind stets End 2 End (von der Quelle bis zur Ergebnispräsentation) nachvollziehbar.
- Flexibel genug, um jederzeit Anpassungen entsprechend veränderter Anforderungen vornehmen zu können.
Der Model Driven Design Ansatz
Im Rahmen unseres Auswahlverfahrens eines Beratungsunternehmens, welches uns unterstützen kann unser DWH (Data Ware House) auf die nächste Evolutionsstufe zu heben, lernten wir den Ansatz des „Model Driven Design for Analytics“ kennen. Hierin erkannten wir, dass dies eine Möglichkeit sein könnte, unsere o.g. Anforderungen zu erfüllen.
Nachfolgend eine Erläuterung des MDD-Ansatzes.
Im Fokus steht die Unterstützung der Analyse & Designphasen durch modellgetriebene Spezifikation und Wiederverwendung relevanter Sachverhalte auf Basis eines zentralen Metadaten Repositories. Durch erweiterbare (Meta-) Modelle wird definiert, in welcher Form und in welchem Detailgrad Informationen erhoben werden müssen.
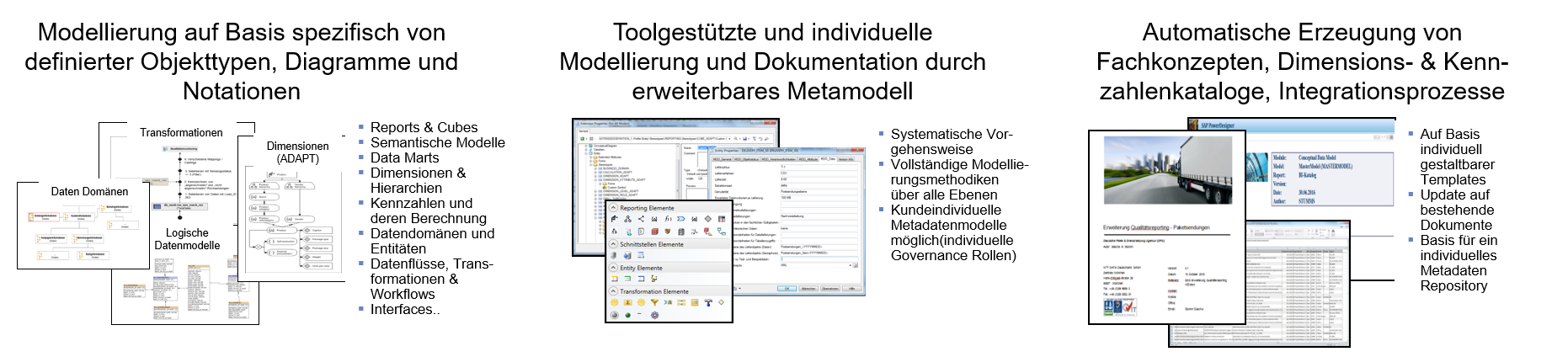
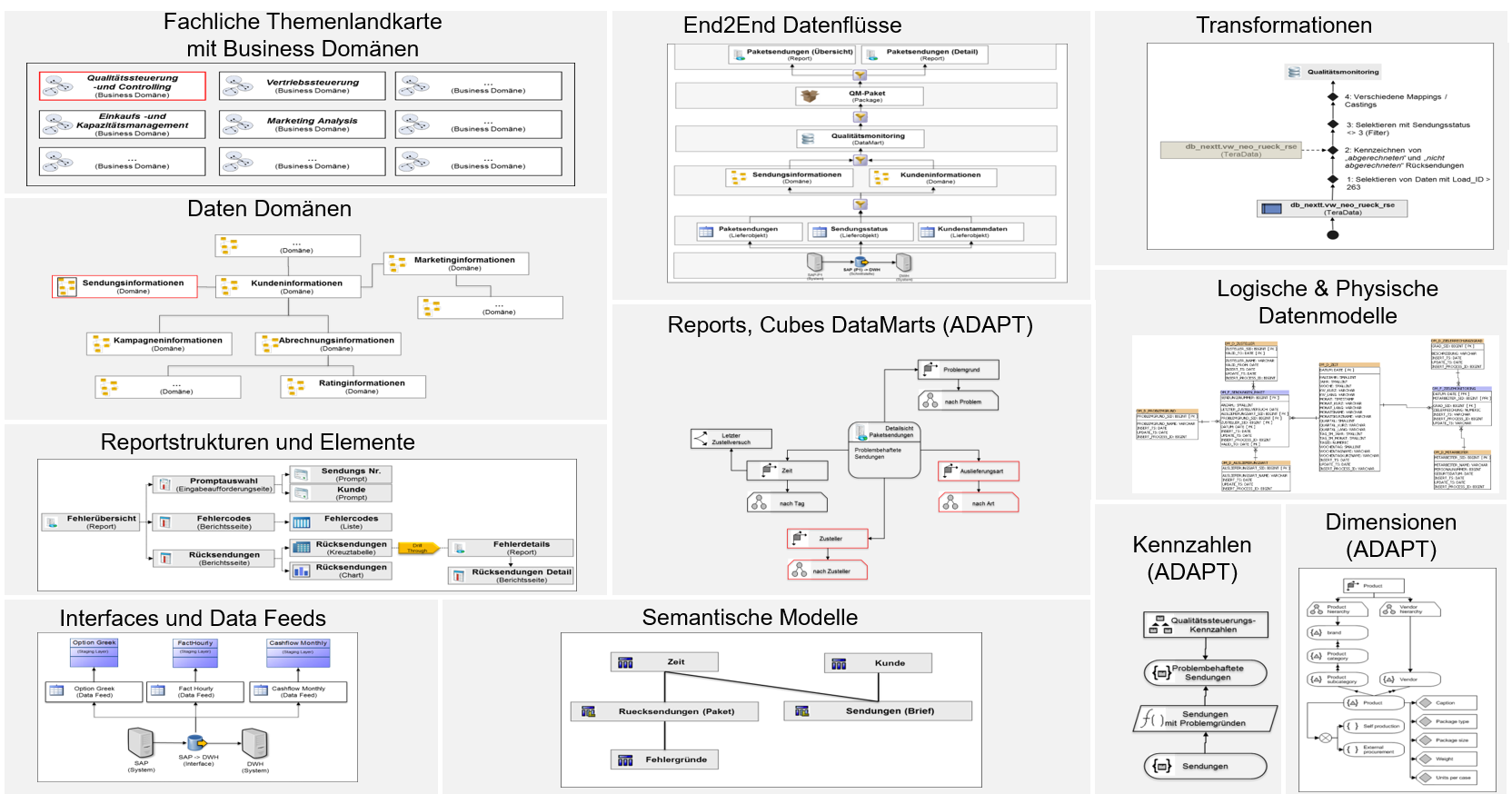
Anwendung finden unterschiedlichste Modellierungsobjekte für verschiedene Sachverhalte und Detailtiefe. Die Modellierungsobjekte sind miteinander verknüpft und ermöglichen flexibel von der Übersichtsebene bis in einzelne Detailtiefen zu navigieren. Nachfolgend ein Auszug der Modellierungsobjekte, die bedarfsgerecht angewendet werden können.
Folgende Vorteile werden mit MDD erreicht:
- Reduzierter Abstimmungsaufwand
- Abstimmungsprozesse zwischen Anforderer und Designer/Entwickler werden formalisiert und fokussieren sich auf die wesentlichen Spezifikationsinhalte
- Konsistenz und Wiederverwendbarkeit
- Identische Sachverhalte werden durch die Verwendung eines zentralen Metadaten Repository gleich und konsistent verwendet und umgesetzt
- Automatisierte Weiterverarbeitung
- Bedarfsorientierte automatische Generierung von Ergebnisdokumenten wie Fachkonzepte, DV-Konzepte, Datenintegrationsprozesse, Metadaten Kataloge
- Transparenzsteigerung
- Durch „Single Point of Documentation” Möglichkeit von Abhängigkeits- und Impactanalysen über alle Modellierungs-und Architekturebenen hinweg
- Vermeidung Missverständnisse
- Anhand von einfachen semantischen Notationen wird fachliche Korrektheit der Spezifikation für Anforderer schnell prüfbar und vor der Implementierung erkennbar
- Compliance-Anforderungen steuerbar
- Durch zeitnahe Dokumentation, an welchen Stellen personenbezogene Daten verwendet und verarbeitet werden (sollen), kann hier bereits eine erste Bewertung der Compliance-Konformität durchgeführt und ggf. erforderliche Anpassungen in der Konzeptionsphase vorgenommen werden.
Weitere Ausbaustufe
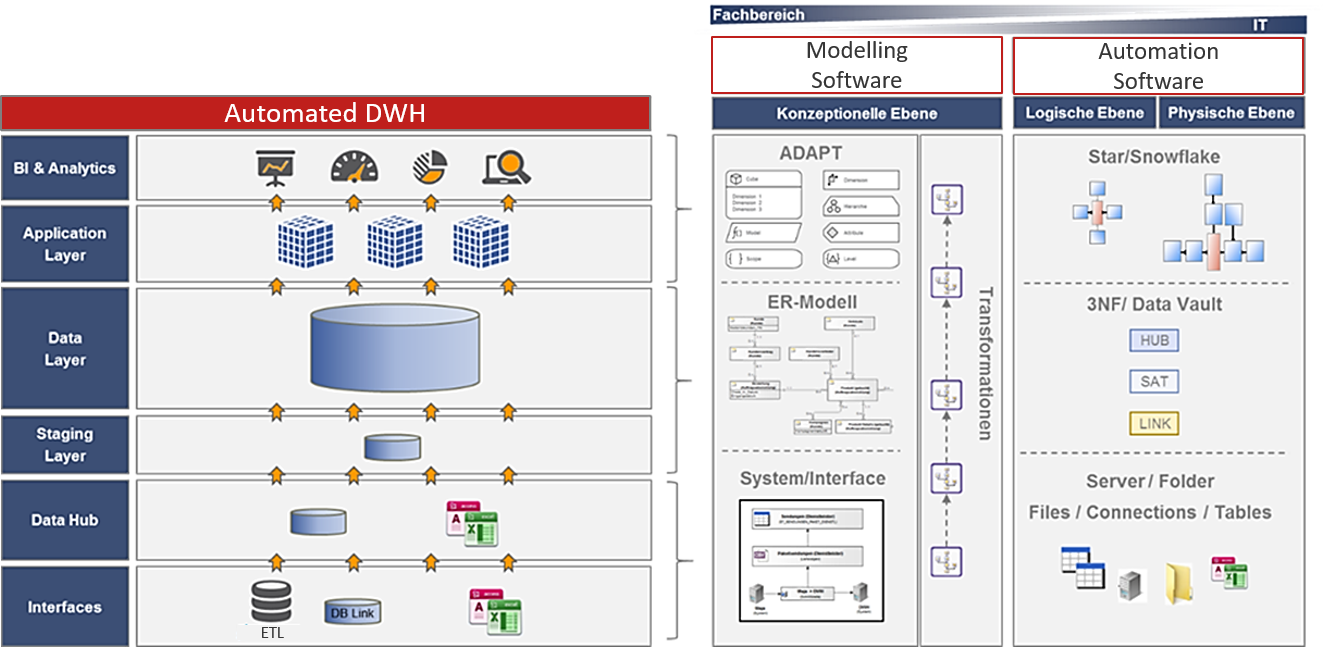
Als eine weitere Ausbaustufe sehen wir die Möglichkeit die metadatenbasierten logischen Modelle mit unserer metadatenbasierten Automatisierungslösung im DWH zu verbinden. Ziel ist es eine ganzheitliche Data Lineage - vom Business bis in die Physik – ableiten zu können. Ein weiteres Ziel ist es verschiedene Metadaten (Quellsysteme, DWH, MDD) sukzessive in einem Metadaten-DWH zu vereinen und somit stetig die Transparenz über unser Datenmanagement zu steigern sowie einen einheitlichen Data Catalog zu etablieren und zu nutzen.
Erste Erfahrungen und Fazit
Bereits im ersten Projekt zeigte sich, wie hilfreich es ist mit Modellen ein einheitliches Verständnis der Anforderungen zwischen den verschiedenen Prozessbeteiligten herzustellen.
Das zweite Projekte profitierte bereits von der einfachen Wiederverwendbarkeit der Informationen bei ähnlich gelagerter Verwendung von Daten und Kennzahlen. In diesem laufenden Projekt entwickeln wir bereits erste einheitliche Guidelines, auf die wir dann weitere Mitarbeiter schulen, um eine hohe Qualität im Datenmanagement gewährleisten zu können.
Bereits recht früh zeigen sich erste Erfolge, zumal sich der MDD Ansatz sehr gut in unsere agile Projektstruktur einpassen lässt. Wir sind überzeugt, dass unser eingeschlagener Weg hilft immer mehr Transparenz über unser Datenmanagement zu erzeugen und stetig die Qualität und Compliance-konformität zu steigern und langfristig zu sichern.
Grundsätzlich denke ich, dass der MDD Ansatz ein weiterer Weg ist, wie Data Governance Mehrwert für Organisationen schaffen kann und die Wettbewerbsfähigkeit sichert und steigert. Wer seine Daten versteht und es schafft verantwortungsvoll damit umzugehen, wird auch die Digitale Transformation gut meistern können.
Lesen Sie auch:
- Data Catalog – Beschleuniger der Datenkompetenz (Data Literacy)
- Data Governance, der Schlüssel zu einer erfolgreichen datenintelligenten Organisationskultur
- Data Governance: Was sind Ihre Unternehmens-Daten wert?
- Data Governance: Vom Data Profiling zur ganzheitlichen Leistungsbewertung von Daten
- Prozessorientierter Data Quality Index erfolgreich einführen
- Datenqualität messen: Mit 11 Kriterien Datenqualität quantifizieren
- Wie Sie schnell bewerten können, ob Sie ein Problem mit der Datenqualität haben
- Logikbäume: Mehr Transparenz zur Wirkung schlechter Datenqualität auf Unternehmensziele
Business Intelligence, Business Analytics, Business Information Excellence, Data Governance, Model Driven Design, Datenmodellierung, Metadatamanagement, Data Catalog, Datenkatalog
- Geändert am .
- Aufrufe: 13712